Model-Based Testing for Dungeons & Dragons
Last time, I modeled a single D&D character. One creature, standing alone in the void, tracking hit points, conditions, and spell slots. The Quint spec (a formal modeling language) for that was around 6,000 lines.
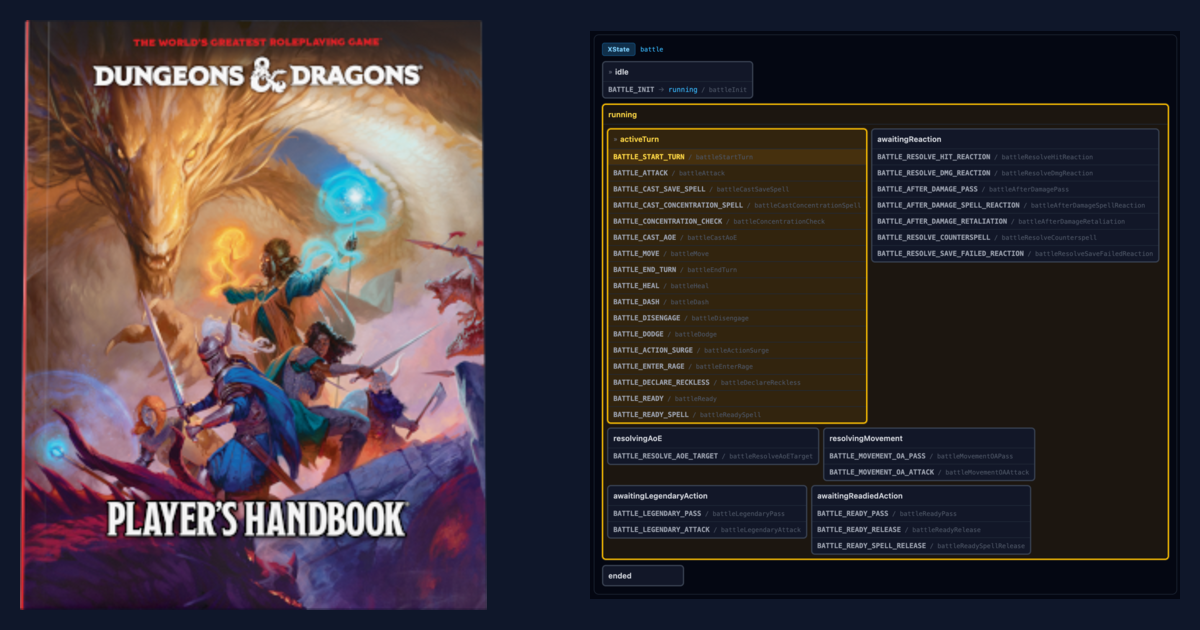
Now I added combat. Not just “a Fighter hits a Goblin with a sword” kind of combat, but the hard part: Counterspell chains, Shield interrupting mid-attack, readied spells holding concentration, Legendary Resistance flipping saves.
Thus, I did the hard part first. Without it, you can’t prove full viability. A spec that handles the simple cases proves nothing, and is akin to a “Todo App project”; the real blockers live in the interactions. If Counterspell chains can deadlock the state machine, or readied-spell concentration can orphan active effects, I needed to know now, not after building three more layers on top.
The battle spec is less than half the creature code. You’d think it amounts to less than half the complexity, but that is far from true.
A single creature’s state space is a flat reducer. A glorified character sheet. Level up, take damage, gain a condition, lose a condition. The state space is large but flat. Combat makes it profound. Two creatures interacting means every action can trigger reactions, every reaction can trigger counter-reactions, and the whole thing nests before anyone’s taken damage. This is where beginner and even proficient players often get confused.
Here’s what the spec covers now: all the character classes (12 of them,) 14 conditions that modify what you can and can’t do. Legendary creatures that act on other creatures’ turns. Counterspell that interrupts spellcasting. Opportunity attacks that fire mid-movement and trigger full attack resolution chains. Both player characters and monsters, with character lists and stat blocks.
The demo replays a scripted arcane battle step by step: Fireball, Counterspell chains, AoE damage, death saves. Step forward, step back, or hit play and watch the interrupt windows open and resolve.
Last time it was one creature in the void. Now it’s all classes, conditions, and a framework for adding any spell or feat whether from the SRD1 or published books. Finally, well past proof of concept!
The Interrupt Chain
A single attack is not a single event.
When one creature attacks another, the rules open a series of interrupt windows — moments where participants can react and alter the outcome mid-resolution. Each one can branch the game state.
Phase 1: The attack hits. The d20 lands, the DM compares it to Armor Class — hit or miss. But the target might cast Shield (+5 AC, potentially flipping the hit to a miss). A Bard’s Cutting Words subtracts a die from the roll. All of this happens after the roll but before the hit is confirmed.
Phase 2: Damage lands. The hit lands. Dice are rolled. But the Rogue has Uncanny Dodge — halve that damage as a reaction. A Monk’s Deflect Attacks subtracts 1d10 plus their Dexterity modifier and level. These fire after the hit but before the damage applies.
Phase 3: A spell is being cast. Spellcasting opens its own window: any creature with Counterspell prepared and a reaction available can force a Constitution save. If the caster fails, the spell fizzles. Use a high enough slot and it auto-succeeds. The Counterspell is itself a spell, so another creature can Counterspell the Counterspell. In the spec, this is a literal stack data structure — push, resolve, pop:
var bSpellStack: List[SpellStackEntry] // push on cast, pop on resolvePhase 4: A save fails. The target fails their saving throw. But the Ancient Dragon has Legendary Resistance — it spends a charge and the save auto-succeeds. This fires after the save result but before the fail effects apply.
Now layer these on top of each other.
A Rogue moves away from an enemy creature. The enemy has an unused reaction, so it gets an Opportunity Attack — one melee attack (even if the attacker has multiattack property, mind me!). That attack enters Phase 1 (can the Rogue cast Shield?), then Phase 2 (Uncanny Dodge?), then after-damage effects (concentration check if the Rogue was concentrating on a spell). All of this happens mid-movement, before the Rogue reaches their destination.
An ally Wizard casts Hold Monster on the Dragon. Phase 3: Counterspell window. The Dragon’s minion tries to counter it. A second ally counter-Counterspells. The stack pops: inner Counterspell resolves first, then the outer one. The spell goes through. The Dragon fails its save. Phase 4: Legendary Resistance. The Dragon burns a charge. Save flipped to success.
After all of this resolves, where does the state machine go back to? It depends on what started it. An attack on your turn resumes the turn. An Opportunity Attack mid-movement resumes movement. An AoE spell moves to the next target. The damage resolution is identical in all cases — only the resume point differs. In the spec, each source carries its own return address as a tagged union:
type AfterDamageReturn =
| ADRActiveTurn
| ADRResolvingAoE(AoESpellCtx)
| ADRResolvingMovement(MovementCtx)
| ADRAwaitingLegendaryAction(LAWindowCtx)
| ADRAwaitingReadiedAction(ReadyWindowCtx)Every time the state machine enters an interrupt chain, it carries the return address with it. When the chain resolves — all reactions offered, all damage applied, all concentration checks done — it pattern-matches on that tag and resumes the correct phase.
The XState machine mirrors the same type and the same pattern match:
// battle-machine-types.ts
type AfterDamageReturn =
| { tag: "ADRActiveTurn" }
| { tag: "ADRResolvingAoE"; aoe: AoESpellCtx }
| { tag: "ADRResolvingMovement"; mv: MovementCtx }
| { tag: "ADRAwaitingLegendaryAction"; la: LAWindowCtx }
| { tag: "ADRAwaitingReadiedAction"; ready: ReadyWindowCtx }
// battle-machine-helpers.ts
function returnToState(r: AfterDamageReturn): PhaseFields {
return Match.value(r).pipe( // effect/Match: exhaustive pattern matching
byTag("ADRActiveTurn", () => PHASE_ACTIVE),
byTag("ADRResolvingAoE", (v) => phaseResolvingAoE(v.aoe)),
byTag("ADRResolvingMovement", (v) => phaseResolvingMovement(v.mv)),
// ...
Match.exhaustive // no default branch — compiler rejects missing variants
)
}Quint pattern-matches on the tag to decide where to go next. XState does the same via Match.exhaustive — which also means adding a new return variant is a compile error until every call site handles it. MBT compares context after every step: if the XState machine routes to the wrong phase, the trace diverges and the seed is logged.
This is why the formal spec matters. The interrupt interactions create a combinatorial state space. The Quint fuzzer explores it; unit tests cover the paths you thought of.
The spec models all of this. But it doesn’t model everything.
What’s Spec vs What’s DM
The spec doesn’t model everything. It models everything mechanically deterministic — given the same inputs, there’s exactly one correct answer. Everything else enters the spec as caller-provided input.
Dice rolls are the simplest case. The spec never generates random numbers. The caller passes rolls as arguments, already resolved. The spec proves that given any roll, the downstream mechanics are correct. Randomness is the caller’s problem.
Cover works the same way. The spec receives it as a typed enum: NoCover | HalfCover | ThreeQuartersCover | TotalCover. It proves the AC and DEX save bonuses for each level. Whether that pillar constitutes half cover or three-quarters cover is DM’s call on geometry they use.
Fun fact: traditionally, Dungeons and Dragons combat geometry is non-Euclidean.
Opportunity attacks push this further. When a creature moves through a threatened area, the spec receives a set of threatening creatures as input, then tests: given any set, does the OA pipeline resolve correctly? It never asks “who’s actually within 5 feet?” — that’s spatial, a different problem entirely. The spec proves the (re)action economy and attack resolution work for any threat configuration the caller provides.
This is a deliberate architectural choice, not a deferral. D&D supports both theatre-of-mind (no map, distances are narrative) and grid-based battlemaps. The DM picks one or improvises a hybrid. A spec that commits to a spatial model is wrong for half the tables. Ours takes spatial facts as inputs and proves the mechanics correct regardless of how the DM represents space.
This pattern generalizes beyond D&D. Any domain with formal rules also has human decision points. The spec proves the mechanical parts correct regardless of what the human decides.
What MBT Actually Caught
So: the spec encodes what the rules prescribe. The XState machine encodes the runtime behavior. When those two disagree, the model-based testing bridge catches it.
The first night of fuzzing produced a thousand and half failures. All from one root cause: the XState machine didn’t derive spell slots from class levels. Every spellcaster started with zero slots. Hand-written tests never caught it — they supplied explicit slot values in fixtures. The fuzzer used the actual class data and immediately noticed that nobody could cast anything.
Fix deployed. New bugs surfaced. Then more. Here’s that night, with auto-fixes done by Claude Code:
20:06 Fuzzing starts. 1,447 failures. One root cause: spell slot init.
21:16 Fix. Three sub-symptoms (slots, pact slots, hit dice) all resolved.
21:32 New bugs: death save divergence, Arcane Recovery flag.
23:07 Paladin Extra Attack missing — bridge forgot Paladin in the list.
00:36 Arcane Recovery: flag not set when target slot already full.
01:08 Defy Death: spec passed total level, not Fighter level.
01:38 First clean cycle.
02:08 Nine consecutive clean cycles. Silence until morning.Each fix uncovered the next layer. Here are the bug classes that kept appearing:
Same-type argument swaps. computeTakeDamage takes immunities, resistances, and vulnerabilities as separate parameters. All three are ReadonlySet<DamageType>. Swap two and TypeScript doesn’t blink2. Your creature is now “resistant” to what it should be vulnerable to. MBT caught this across 19 seeds — every damage calculation in the game was wrong.
The spec was wrong, not the implementation. Defy Death is a Champion Fighter feature: death save rolls of 18-19 count as natural 20s. The spec passed config.level (total character level) instead of config.classLevels.get(Fighter). A level-18 Barbarian got the Champion’s feature. The XState machine was actually correct — it used the fighter class level. MBT found the divergence and pointed at the spec. This subverts the usual narrative: the “source of truth” had the bug.
Invariant fuzzer finds rules violations. The Counterspell chain had a slot-expenditure timing bug. Slot spend was deferred until resolution, so when creature A casts Fireball and D counterspells, A’s slotExpendedThisTurn is still false — making A eligible to counter-counterspell with a second slot in the same turn. The invariant spellStackDistinctCasters caught it on six seeds the first night. This wasn’t a code bug. It was a spec-level design flaw that violated the SRD’s “one spell slot per turn” rule.
Silent swallowing via default branches. A switch statement in resolveSpellEntry had a default branch that silently ate PCECounterspell entries in deep Counterspell chains. The spell vanished. No error, no crash, just wrong behavior. Moving to effect/Match with Match.exhaustive (which forbids default branches) killed this entire bug class at compile time3.
Cross-branch state sync. XState models parallel state regions: damage tracking, turn phases, spellcasting running concurrently. A creature stabilizes via start-of-turn healing in one branch while another branch still accepts death saves. Dead creatures stopped processing effects because of a break where a continue belonged — skipping all remaining effects after the first.
Condition implication cascades. Paralyzed implies Incapacitated. Remove Paralyzed, and Incapacitated should lift — unless the creature is also Stunned, which independently implies Incapacitated. The spec tracks implication sources as a set: incapacitatedSources: Set[IncapSource]. The XState machine used a Set spread pattern ([...set].filter(...)) that silently failed to remove the source on certain paths. The creature stayed Incapacitated after all sources were gone. A downstream invariant (incapNotConcentrating, which asserts incapacitated creatures can’t concentrate) caught the inconsistency: a creature was concentrating on a spell while the machine said it was incapacitated.
These aren’t exotic edge cases but the normal consequence of a state space too large to enumerate by hand.
12,700 Arguments, Machine-Checked
The bugs above are things the spec found in my implementation. The QA pipeline finds bugs that players found in the rules.
I scraped roughly 12,700 community Q&A entries: Reddit r/onednd threads, RPG Stack Exchange questions, the Sage Advice Compendium. Each goes through a conveyor: an LLM classifies it (“is this a Rules As Written mechanics question?”). A second LLM translates the accepted answer into a Quint assertion. The assertion gets typechecked, and quint test runs it. Pass or fail.
Nearly a thousand survived to become runnable assertions4. The rest either aren’t RAW questions or the LLM’s generated code fails to typecheck. That ~40% failure rate is fine — the spec is the filter. If Claude invents a function that doesn’t exist, the typecheck catches it. If it misinterprets a ruling, the spec disagrees. Either way: signal.
The Prone Lock is the simplest. Grapple a creature, shove it prone. Its speed drops to 0, and standing from prone costs half your speed — which is half of zero. Three function calls confirm the lock: grapple succeeds, shove succeeds, effectiveSpeed == 0. The creature can’t move until the grapple ends.
Grapple Leapfrog. An early test from when the project still used 2014 rules. Two players cover 60 feet between them with only 30 feet of speed each. Bob grapples Alice (she willingly fails). Under the 2014 rules, his speed is halved while dragging. He Dashes to double it back to 30, carries her 30 feet, releases. Alice’s turn: same thing, opposite direction. Net displacement: 60 feet. The 2024 rules changed grappling to cost 1 extra foot per foot moved, which closes the drag-and-release exploit.
run qa_grapple_leapfrog = {
val bob = freshCreature(30)
val alice = freshCreature(30)
// 2014 rules: speed halved while grappling same-size creature
val bobTurn = pStartTurn(TEST_CONFIG, bob, Unarmored, 0, true, false)
val bobDashed = pUseAction(bobTurn, bob, ADash) // 15 + 15 = 30
val aliceTurn = pStartTurn(TEST_CONFIG, alice, Unarmored, 0, true, false)
val aliceDashed = pUseAction(aliceTurn, alice, ADash)
assert(bobDashed.movementRemaining + aliceDashed.movementRemaining == 60)
}Ogre vs. Animated Armor. Animated Armor is a construct monster — low Strength, high AC. The 2024 rules changed grappling from an opposed Athletics check to a saving throw against a flat DC: 8 + STR modifier + proficiency. Under the old rules, the Ogre’s Athletics made it hard to grab. Under the new rules, what matters is the target’s save bonus. An Ogre with its modest Dexterity is easy to grapple. Animated Armor, despite being weaker overall, has better saves. The community noticed this inversion.
// DC = 8 + STR mod + proficiency = 8 + 3 + 2 = 13
// Ogre: DEX save +0 → needs 13+ on d20, fails most rolls
// Animated Armor: STR save +4 → needs 9+, succeeds often
pure def pGrappleShoveDC(strMod, profBonus) = 8 + strMod + profBonusSame grappler, same DC, very different outcomes depending on the target’s save bonus rather than its combat stats.
The pipeline doesn’t require Reddit threads exclusively. I’ve been experimenting with feeding it game session recordings — actual play transcripts where a DM makes a ruling mid-combat. Messier than Stack Exchange, but those are the rulings people actually play with.
The Feature Surface
The spec has 62 safety invariants. They deserve a closer look. You already know the instinct behind them — you just call it different things depending on where you are in the stack.
You write assert() at the top of a function. Precondition, postcondition, “this should never be null here.” TigerBeetle’s TigerStyle is the most disciplined version of this: paired assertions at call site and definition, checking both what should and what should not be true. Their principle: assertions downgrade catastrophic correctness bugs into liveness bugs. Crash early, corrupt nothing. Same instinct: state something that must hold, crash if it doesn’t.
You put a Zod5 schema at your API boundary. Same instinct, different layer. You’re not checking logic. You’re checking shape. Right structure, right types, values within range. The parser runs once, at the edge, and everything downstream trusts the output. It’s a gate, not a monitor.
You write a property-based test. Same instinct, scaled up. Instead of one example, you generate thousands of random inputs and check that a property holds across all of them. I used this approach for property-based testing of temporal graph storage. Deterministic seeds, millions of scenarios, properties as the oracle. The Quint MBT fuzzer works the same way: random traces, seed-reproducible, properties checked at every step.
A Quint invariant is the same instinct taken to its limit. The model checker doesn’t sample. It explores every reachable state the spec can produce. “HP never exceeds max” isn’t tested against a thousand random creatures. It’s proven for every creature the spec can construct. That’s the jump: from “this held on all inputs I tried” to “this holds in every state the system can reach.”
If you already validate at the boundary and assert at runtime, you know what invariants are. The spec just checks them across every state the system can reach instead of the states your tests happen to visit.
Twelve classes, levels 1 through 20, each with its SRD subclass. Fourteen conditions with implication chains — apply Paralyzed and Incapacitated follows; remove Paralyzed and the system knows whether Incapacitated should stay or go. Legendary creatures with Legendary Actions, Legendary Resistance, and Recharge abilities. Weapon Mastery covering all eight properties across thirty-eight weapons. Environmental rules: falling, suffocation, vision and light, underwater combat. Sixty-two safety invariants guarding the whole thing.
The full feature table has the details. It’s past the proof-of-concept stage.
Why This Exists, and Where It Goes
The SRD 5.2.1 is released under CC-BY-4.0 — unusually permissive for game content. That’s why this project is possible. But the SRD is a subset of the full Player’s Handbook: one subclass per class, almost no feats, a fraction of the spells. Wizards of the Coast publishes enough to build on, not enough to replace the book. The spec models what the SRD gives us. The architecture is designed so that non-SRD content — additional subclasses, feats, spells from the PHB or homebrew — can plug into the mechanical layer without touching the core spec. Mechanics live in Quint, content lives in TS.
The spec isn’t tied to one implementation. The Quint model is the source of truth; XState happens to be the first runtime that mirrors it. But the same traces that validate XState can validate any implementation — Rust, Go, a Godot plugin. The MBT bridge doesn’t care what language the target is written in. It generates traces from the spec and compares state. If the states match, the implementation is conformant.
This gets interesting with coding agents. An agent can read the Quint spec, generate an implementation in any language, and the MBT pipeline immediately tells it whether the output is correct — not “compiles” correct, not “passes the tests I wrote” correct, but “matches the formal spec across thousands of random traces” correct. The feedback loop is foolproof: generate, run traces, fix divergences, repeat. The spec is the oracle the agent checks itself against. The perfect agentic harness.
Not every project needs a formal spec. This one did because the rules are written down but the interactions are combinatorial, correctness matters, and a large community has already found the edge cases. The implementation is a state machine, which maps naturally to TLA-family specs.
This isn’t the first attempt. MongoDB published their TLA+ conformance checking work in June 2025. Spec as oracle, trace replay against implementation. We do the same thing with Quint and XState, on a domain with community Q&A corpus feeding the spec validation.
Other domains fit the pattern: financial regulations, protocol implementations, medical decision trees. Anywhere with written rules, combinatorial interactions, and a correctness requirement.
Try It
- Demo: dnd-quint.dearlordylord.com
- Repo: github.com/dearlordylord/5e-quint
- First post: Formally Specifying Dungeons and Dragons rulebooks
- Quint: github.com/informalsystems/quint
- MBT bridge: @firfi/quint-connect
- XState: xstate.js.org
D&D is a trademark of Wizards of the Coast. This is unofficial fan content permitted under the Fan Content Policy.
Footnotes
-
The System Reference Document 5.2.1 — Wizards of the Coast publishes the core D&D rules under CC BY 4.0, so anyone can build on them. ↩
-
Actually, branded types could catch this at compile time — make
Immunities,Resistances, andVulnerabilitiesstructurally identical but nominally distinct, and the swap becomes a type error. We caught it at the MBT layer instead, but the type-level fix exists. ↩ -
I wrote about why default branches are dangerous and how exhaustive matching prevents this class of bugs in Never Have I Ever. ↩
-
This run was against the first version of the spec (single creature, no combat). The battle spec covers more surface now, so a fresh run would likely produce more assertions. I burned all my claude tokens this week, so that’s a future exercise. ↩
-
Zod is a TypeScript-first schema validation library. You declare the shape of your data, and Zod parses and validates it at runtime — turning unknown input into typed, trusted output. Zod is the most popular, but far from the only one. ↩